Introduction
Raft is a consensus algorithm for managing a replicated log. It was designed to be easy to understand, implement, and efficient. Raft is a leader-based algorithm, where the leader is responsible for managing the replication of the log. The leader is elected by the followers, and the leader is responsible for managing the replication of the log. Raft is designed to be fault-tolerant and to handle network partitions.
In this lab, we will implement the leader election part of the Raft algorithm.
State Machine
The state machine for the Raft leader election algorithm has three states: follower, candidate, and leader. The follower state is the initial state of the state machine. And all servers have a random election timeout, this timer is reset to a random value whenever a server receives a heartbeat (AppendEntries RPC) from the leader.
Here is a table that shows the transitions between the states:
| Current / Next | Follower | Candidate | Leader |
|---|
| Follower | N/A | Election timeout,start a new election | N/A |
| Candidate | Discovers current leader, or new term | Election timeout, no leader was elected,start a new election | Win election |
| Leader | Discovers server with higher term | N/A | N/A |
Or you can represent the state machine as figure 4 in the Raft paper:
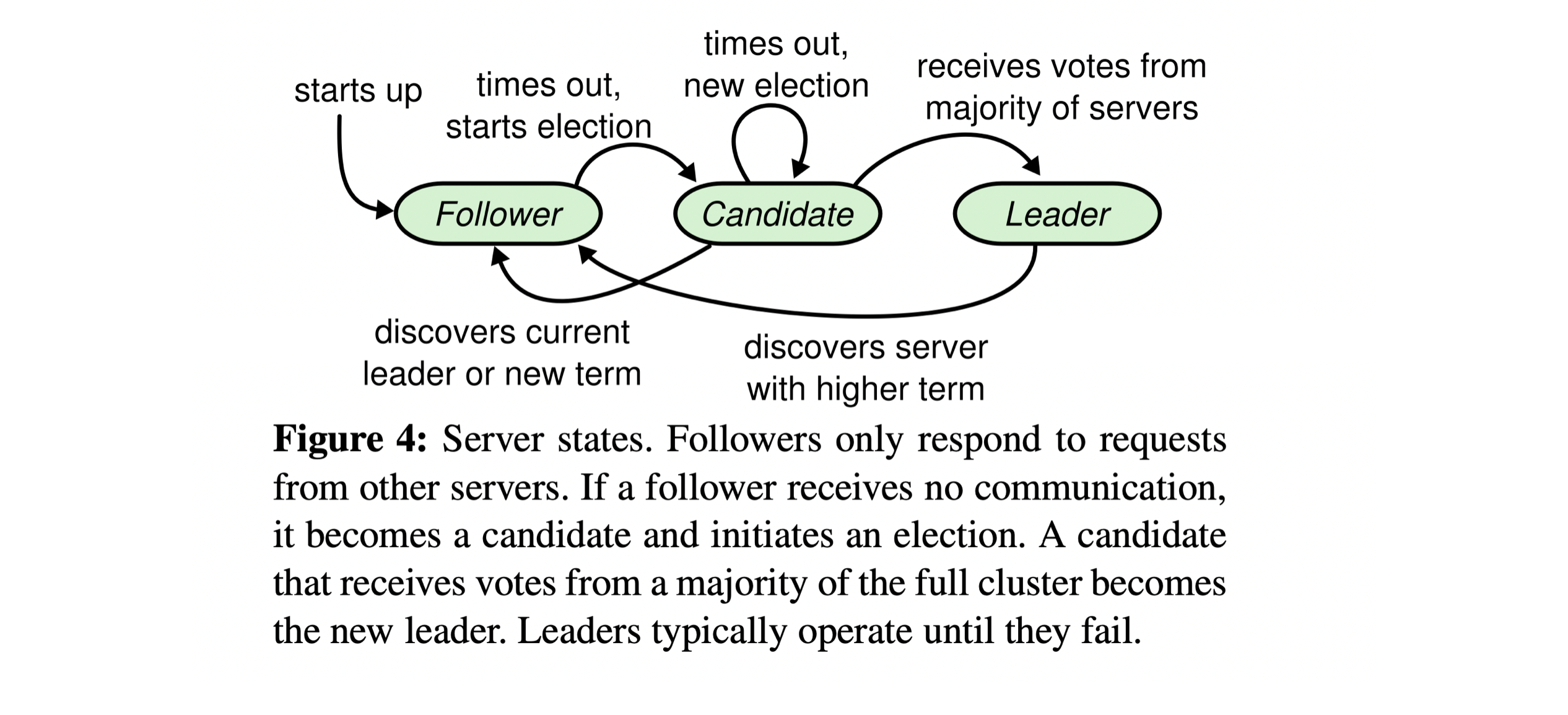
So you can write the state machine as a main loop like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| type State int8
const (
State_Follower State = iota
State_Candidate
State_Leader
)
func (rf *Raft) ticker() {
for rf.killed() == false {
ms := 300 + (rand.Int63() % 300)
rf.mu.Lock()
state := rf.state
rf.mu.Unlock()
switch state {
case State_Leader:
select {
case <-rf.toFollowerCh:
DPrintf("[%d] Server %d from leader to follower", rf.currentTerm, rf.me)
case <-time.After(time.Duration(20) * time.Millisecond):
rf.broadcastAppendEntries()
}
case State_Follower:
select {
case <-rf.grantVoteCh:
case <-rf.recvCh:
// DPrintf("[%d] Server %d recv heartbeat", rf.currentTerm, rf.me)
case <-time.After(time.Duration(ms) * time.Millisecond):
rf.startElection(State_Follower)
}
case State_Candidate:
select {
case <-rf.toFollowerCh:
DPrintf("[%d] Server %d from candidate to follower", rf.currentTerm, rf.me)
case <-rf.toLeaderCh:
rf.mu.Lock()
rf.toLeader()
rf.mu.Unlock()
rf.broadcastAppendEntries()
case <-time.After(time.Duration(ms) * time.Millisecond):
rf.startElection(State_Candidate)
}
}
}
}
|
Heartbeat
Because we did’t implement the log replication part of the Raft algorithm, we need to simulate the heartbeat mechanism to prevent the leader from stepping down. The heartbeat mechanism is simple, the leader sends an AppendEntries RPC to all followers periodically.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| func (rf *Raft) broadcastAppendEntries() {
for i := range rf.peers {
if i == rf.me {
continue
}
go func(i int) {
rf.mu.Lock()
args := &AppendEntriesArgs{
Term: rf.currentTerm,
}
rf.mu.Unlock()
reply := &AppendEntriesReply{}
if ok := rf.sendAppendEntries(i, args, reply); !ok {
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
if reply.Term > rf.currentTerm {
rf.toFollower(reply.Term)
}
}(i)
}
}
|
When server receive an AppendEntries RPC, it will check the term of the RPC, if the term is greater than the current term of the server, the server will step down to the follower state. And we need to send a signal to the recvCh channel to notify the main loop to reset the election timer.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| type AppendEntriesArgs struct {
Term int
}
type AppendEntriesReply struct {
Term int
}
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if args.Term > rf.currentTerm {
rf.toFollower(args.Term)
}
reply.Term = rf.currentTerm
sendToChannel(rf.recvCh)
}
func (rf *Raft) toFollower(term int) {
state := rf.state
rf.currentTerm = term
rf.state = State_Follower
rf.voteFor = -1
if state != State_Follower {
sendToChannel(rf.toFollowerCh)
}
DPrintf("[%d] Server %d become follower", rf.currentTerm, rf.me)
}
|
Leader Election
When a server’s election timer times out, it will start a new election. The server will increase its current term and vote for itself. Then it will send a RequestVote RPC to all other servers. If the server receives a majority of votes, it will become the leader, then send AppendEntries RPC to all followers periodically.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
| type RequestVoteArgs struct {
Term int
CandidateId int
// LastLogIndex int
// LastLogTerm int
}
type RequestVoteReply struct {
Term int
VoteGranted bool
}
func (rf *Raft) toCandidate() {
if rf.state == State_Leader {
panic("Leader cannot be candidate")
}
rf.resetChannels()
rf.currentTerm++
rf.state = State_Candidate
rf.voteFor = rf.me
}
func (rf *Raft) startElection(fromState State) {
rf.mu.Lock()
defer rf.mu.Unlock()
DPrintf("[%d] Server %d start election from state %v", rf.currentTerm, rf.me, fromState)
if rf.state != fromState {
DPrintf("[%d] Server %d election race from %v to %v", rf.currentTerm, rf.me,
fromState, rf.state)
return
}
rf.toCandidate()
args := &RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
}
ch := make(chan bool)
for i := range rf.peers {
if i == rf.me {
continue
}
go func(i int) {
reply := &RequestVoteReply{}
_ = rf.sendRequestVote(i, args, reply)
rf.mu.Lock()
if reply.Term > rf.currentTerm {
rf.toFollower(reply.Term)
}
rf.mu.Unlock()
ch <- reply.VoteGranted
}(i)
}
go func() {
votedCount := 1
for {
idx := <-ch
if idx {
votedCount++
}
if votedCount > len(rf.peers)/2 { // be leader
DPrintf("[%d] Server %d recv vote %d", rf.currentTerm, rf.me, votedCount)
sendToChannel(rf.toLeaderCh)
return // finish election
}
}
}()
}
|
When a server receives a RequestVote RPC, it will check the term of the RPC, if the term is greater than the current term of the server, the server will step down to the follower state and vote for the candidate. If the server has already voted for another candidate in this term, it will reject the vote. In additional, if we have implemented the log replication part of the Raft algorithm, we need to check the log of the candidate is up-to-date, if not, we will reject the vote.
If a server votes for the candidate, it will reset its election timer for buying the candidate more time to win the election.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
DPrintf("[%d] Server %d recvied voted request from %d", rf.currentTerm, rf.me, args.CandidateId)
if args.Term < rf.currentTerm { // candidate's Term is lower
reply.Term = rf.currentTerm
reply.VoteGranted = false // not grant
return
} else if args.Term > rf.currentTerm {
rf.toFollower(args.Term)
}
// grant
reply.Term = rf.currentTerm
if rf.voteFor < 0 || rf.voteFor == args.CandidateId {
rf.voteFor = args.CandidateId
reply.VoteGranted = true
DPrintf("[%d] Server %d voted for %d", rf.currentTerm, rf.me, rf.voteFor)
}
sendToChannel(rf.grantVoteCh)
return
}
|
If no servers get a majority of votes, the election will fail, and the server will start a new election after the election timeout, until a server wins the election, like the figure 5 in the Raft paper.
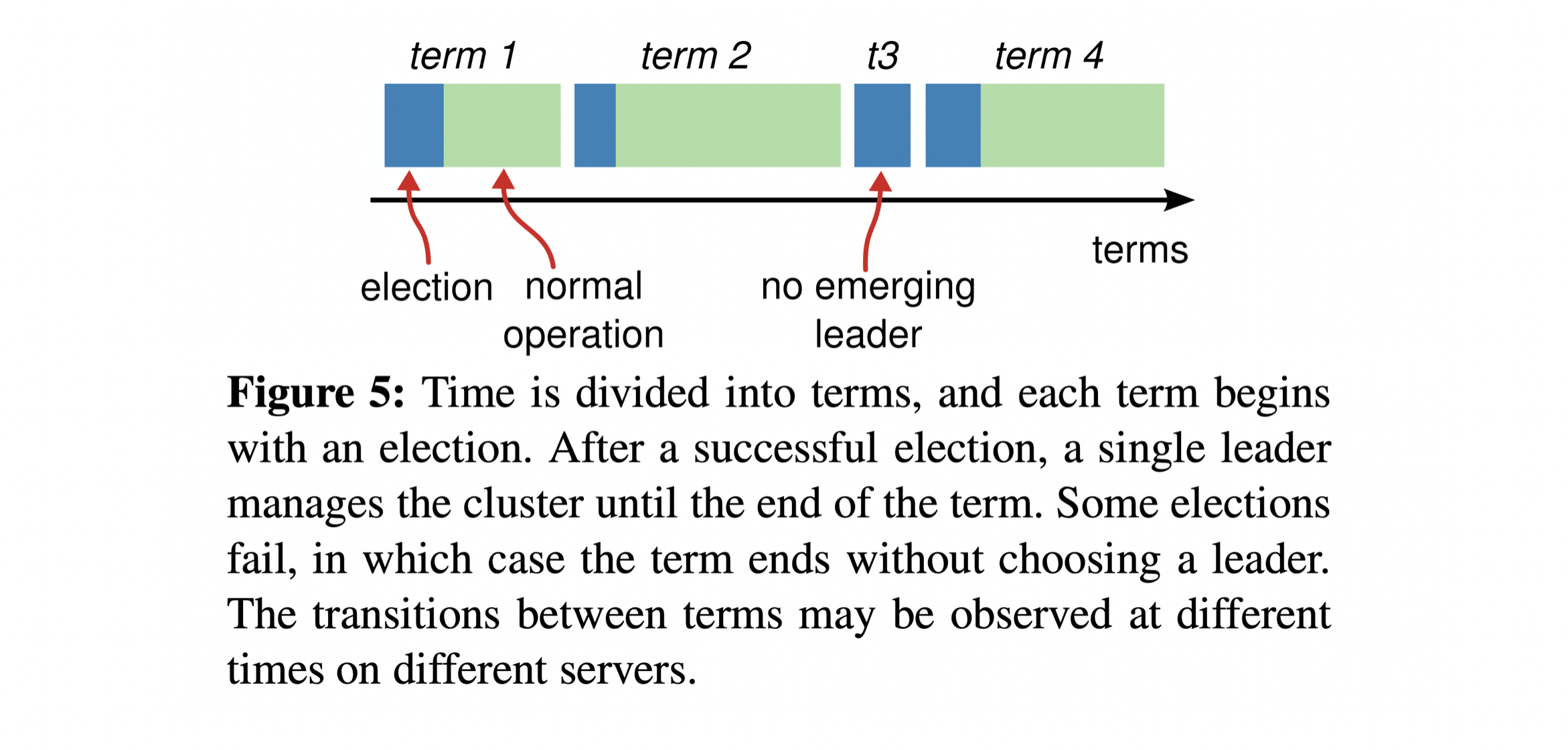
Randomizing the election timeout can reduce the chance of split votes, because it reduces the chance that two servers will time out at the same time.
Another point to note is that the election timeout should be much larger than the heartbeat interval, so that the leader can send heartbeats to the followers before the followers start a new election.
Conclusion
In this lab, we implemented the leader election part of the Raft algorithm. We implemented the state machine, the heartbeat mechanism, and the leader election mechanism. In the next lab, we will implement the log replication part of the Raft algorithm.
The Raft paper is a great resource for understanding the Raft algorithm. It provides a detailed explanation of the algorithm and its properties. I highly recommend reading it if you want to learn more about Raft.
My implementation of this lab can be found on GitHub, hope it helps you understand the concepts better. If you have any questions or feedback, feel free to send me an email. Thank you for reading!